· model lake · 6 min read
Amalur
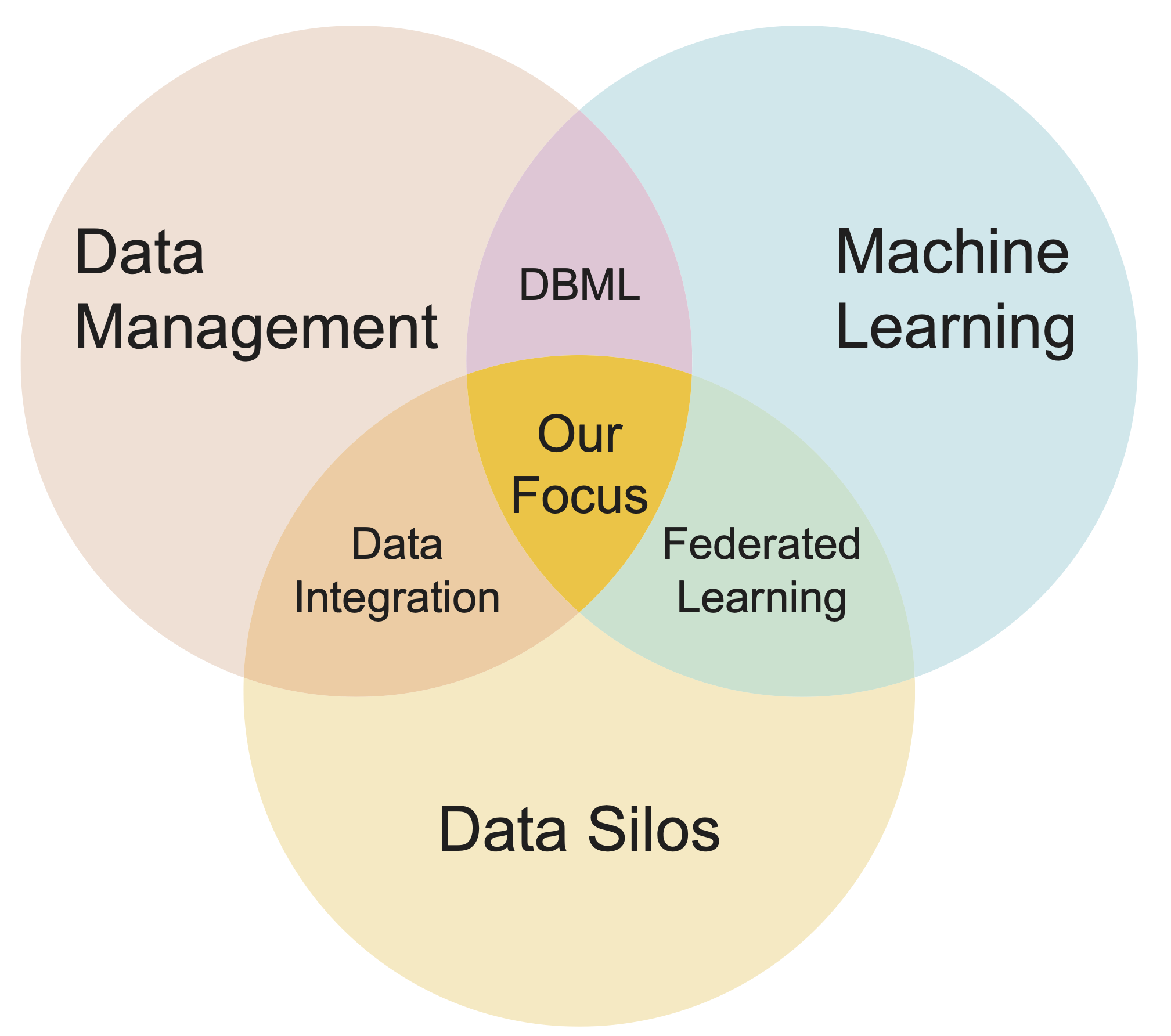
The Convergence of Data Integration an Machin Learning
Abstract
Machine learning (ML) training data is often scat- tered across disparate collections of datasets, called data silos. This fragmentation poses a major challenge for data-intensive ML applications: integrating and transforming data residing in different sources demand a lot of manual work and com- putational resources. With data privacy constraints, data often cannot leave the premises of data silos; hence model training should proceed in a decentralized manner. In this work, we present a vision of bridging traditional data integration (DI) techniques with the requirements of modern machine learn- ing systems. We explore the possibilities of utilizing metadata obtained from data integration processes for improving the effectiveness, efficiency, and privacy of ML models. Towards this direction, we analyze ML training and inference over data silos. Bringing data integration and machine learning together, we highlight new research opportunities from the aspects of systems, representations, factorized learning, and federated learning
Amalur overview
We are currently developing Amalur, a machine learning system that is based on our work on data lakes and model zoos. With DI metadata, Amalur solves the challenges of efficient training and inference of ML models over data silos and reducing the manual work of integrating the data. Figure 3 provides a high-level overview of Amalur with key components relevant to this paper. Our proposed system is designed to support both materialized and factorized data; however, while learning on materialized data is well established, our primary focus is to explore factorization.
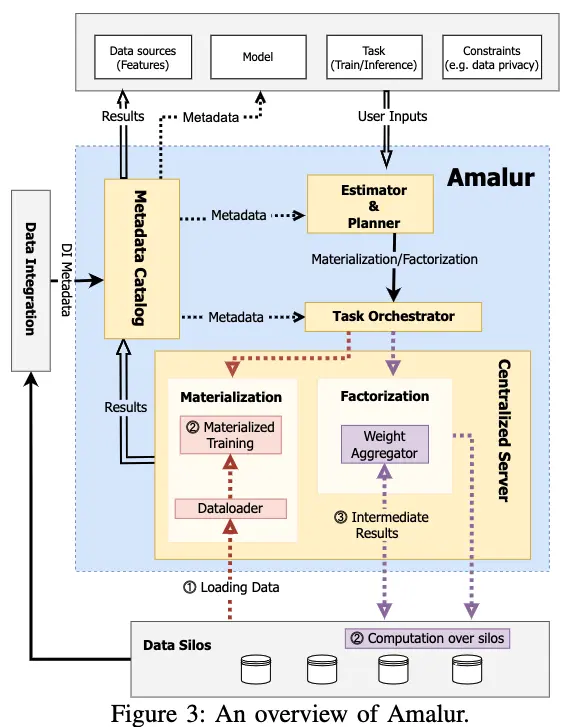
User inputs. Amalur empowers users, including domain ex- perts like physicians or data scientists, to run predictive or ML model training tasks on data silos. Through the metadata pro- vided by the catalog, users can choose the desired features and relevant data silos. They can also initiate model training using either custom models or Amalur’s built-in ML models with metadata from the catalog. Furthermore, specific constraints, such as data privacy regulations like the GDPR, can be specified by individual users or particular silos. execute the input task over silos: materialization and factoriza- tion. We have developed an initial cost estimator utilizing basic hardware information and the computational complexity of the target model. We elaborate on the cost estimator’s theoretical foundations and preliminary results in Sec. V. The planner identifies the appropriate physical operators and generates an execution plan for task orchestration.
Task orchestrator and dispatcher. The execution plan from the planner is translated into specific programs tailored to the training approach, i.e., factorization, materialization, or FL, and the execution environment, such as TensorFlow, PyTorch, Spark, or ONNX. For materialization, Dataloader pulls data from the silos for processing. Model training or inference will be performed in the centralized server. Alternatively, if factorization is preferred, programs are sent to remote silos as the metadata dictates, i.e., silo location, ensuring they reach the appropriate data location. The main computations are performed over each silo.
Aggregator. For factorized learning and federated learning, a crucial component is the aggregator. Some computations are pushed to the silos while a central server aggregates the results. The computations are performed locally, and the parameters are learned globally. The role of the aggregator is to collect the result of local computations and then distribute the loss to the silos and aggregate the gradient of the parameters.
Amalur workflows for ML training and inference
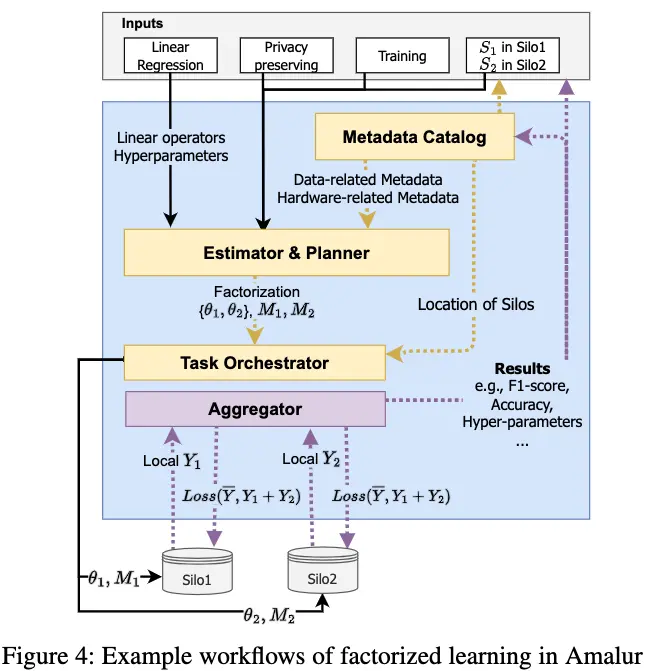 With the core components in Amalur being introduced, we will explain the main workflow among the components in Figure 4. Given the user inputs in Amalur, different workflows are performed: either performing inference or training, either factorizing or materializing the data, etc. Amalur allows users to determine the data sources and models. If there is available DI metadata, Amalur will provide data sources that can be connected. To increase the effectiveness of ML training, a user can select feature columns from the available schemata. Model-related metadata is also retrieved from the metadata catalog and provided to users, which enables them to decide what algorithm and hyper- parameters to use. Users may use their customized model and hyper-parameter sets. In the input phase, the user selects data sources (e.g., name of the table, name of the schema), chooses the model, and determines the task (classification or regression) and constraints (e.g., privacy). With the inputs, model training or inference will be performed. In the end, all results, which include predictive outcomes and trained models, are gathered in a centralized cluster. Concurrently, the system logs the training or inference method (material- ization/factorization), the hyper-parameters, and performance (e.g., F1-score, runtime) in the metadata catalog, making them accessible for future reference and used by other users. Below, we will introduce the training and inference in more detail.
With the core components in Amalur being introduced, we will explain the main workflow among the components in Figure 4. Given the user inputs in Amalur, different workflows are performed: either performing inference or training, either factorizing or materializing the data, etc. Amalur allows users to determine the data sources and models. If there is available DI metadata, Amalur will provide data sources that can be connected. To increase the effectiveness of ML training, a user can select feature columns from the available schemata. Model-related metadata is also retrieved from the metadata catalog and provided to users, which enables them to decide what algorithm and hyper- parameters to use. Users may use their customized model and hyper-parameter sets. In the input phase, the user selects data sources (e.g., name of the table, name of the schema), chooses the model, and determines the task (classification or regression) and constraints (e.g., privacy). With the inputs, model training or inference will be performed. In the end, all results, which include predictive outcomes and trained models, are gathered in a centralized cluster. Concurrently, the system logs the training or inference method (material- ization/factorization), the hyper-parameters, and performance (e.g., F1-score, runtime) in the metadata catalog, making them accessible for future reference and used by other users. Below, we will introduce the training and inference in more detail.
Model training. After Amalur receives the inputs from a user, the cost estimator will determine the computation strategy for training, i.e., to materialize or factorize, with metadata from the inputs and metadata catalog. For materialization, Amalur will integrate the source datasets and generate the target table in the centralized server, and training will be performed on the server. For factorization, the model is decomposed and pushed down to silos. When privacy constraints are present, Amalur executes privacy-aware model training processes over the silos, i.e., federated learning, which we elaborate in Sec. VI-A. Figure 4 depicts a workflow for ML model training in a factorized manner. The planner will split the model into the parameters θ1, θ2 along with the DI metadata M1, M2, which are pushed to Silo1 and Silo2 for computations respectively. Subsequently, the central server will collect the computations and aggregate the result, i.e., Y1 from Silo1, computes the loss calculated from Loss( ̄Y , Y1 + Y2) which is sent back to the silos for gradient updates. Once the loss meets a predefined criterion, a central orchestrator records performance metrics in the metadata catalog. In addition to illustrated workflow, due to privacy considerations in FL, the partial parameters are stored locally within the silos.
Model inference. A user can select a specific model and per- form model inference if models are available for the prepared dataset. Like model training, the cost estimator determines whether the computation is performed in a factorized or mate- rialized manner. Model inference in a materialized manner is similar to model training. Inference in a factorized manner is slightly different, with only the local predictive results being sent to the centralized aggregator to generate the predictive results, while nothing is returned from the server.
Conclusion and reference
In this work, we have explored the possibilities of bringing data integration and machine learning together. Toward this direction, we have proposed a data integration-aware ML system Amalur, which supports machine learning training and inference over silos. We have inspected the promising challenges of representing DI metadata and utilizing it for factorized and federated learning. We envision this work as one of the first steps towards bridging the recent advances in machine learning with the well-studied traditional data integration field.
Users can read the full paper here.