· model lake · 9 min read
TransferGraph
Model Selection with Model Zoo via Grap Learning
Abstract Pre-trained deep learning (DL) models are increas- ingly accessible in public repositories, i.e., model zoos. Given a new prediction task, finding the best model to fine-tune can be computationally intensive and costly, especially when the number of pre-trained models is large. Selecting the right pre-trained models is crucial, yet complicated by the diversity of models from various model families (like ResNet, Vit, Swin) and the hidden relationships between models and datasets. Existing methods, which utilize basic information from models and datasets to compute scores indicating model performance on target datasets, overlook the intrinsic relationships, limiting their effectiveness in model selection. In this study, we introduce TransferGraph, a novel framework that reformulates model selection as a graph learning problem. TransferGraph constructs a graph using extensive metadata extracted from models and datasets, while capturing their inherent relationships. Through comprehensive experiments across 16 real datasets, both images and texts, we demonstrate TransferGraph’s effectiveness in capturing essential model-dataset relationships, yielding up to a 32% improvement in correlation between predicted performance and the actual fine- tuning results compared to the state-of-the-art methods.
Introduction
Today, many pre-trained models are available in public online platforms, e.g., HuggingFace, TensorFlow Hub, and PyTorch Hub. Such repositories of pre-trained models are referred to as model zoos. Model zoos have been widely adopted in recent years, as they offer convenient access to a collection of pre-trained models, including cutting-edge deep learning architectures. This lowers the expertise bar- rier, enabling non-expert individuals to apply complex deep learning models in their applications. Utilizing a model zoo for fine-tuning facilitates the adaptation across a wide range of target datasets, which have varying quantities of training data [2]. In addition, by fine-tuning pre-trained models from the model zoo, machine learning practitioners can bypass the need for training from scratch—a resource-intensive process, resulting in significant savings in both development time and computational resources.
The practical choice is to identify pre-trained models that exhibit promising performance even without fine-tuning, i.e., model selection. As in Figure 1, given a target dataset and sev- eral pre-trained models over existing datasets, model selection aims to rank and select optimal candidates from the model zoo to perform fine-tuning. Different strategies may yield disparate rankings of the candidates.
Existing studies mainly focus on extracting information about the pre-trained models and datasets, and mapping model features to the target dataset labels to measure the model transferability. The efficacy of features is expected to diminish as the source dataset (training dataset of the pre- trained model) and target dataset become less similar [9]. Another approach, exemplified by Amazon LR [10], learns the pattern of model performance by using metadata (e.g., model architecture, data size) to train a regression model. The mechanism of the previous methods is limited to applying model representations extracted from the learned parameters or features constructed from metadata, overlooking the deeper connections inherent among models and datasets. Our work advances beyond existing studies by incorpo- rating the prior knowledge of fine-tuning and transferabil- ity scores (e.g., LogME), representing this information through weighted connections between models and datasets. We borrow the inspiration from data management systems for data repositories, such as data lakes. For managing a collection of datasets, a common approach is to structure these datasets as graphs. This involves representing tables as nodes and their relationships as edges. For instance, an edge can indicate that two tables are semantically similar. For the model selection problem, rich relationships exist not only between models and datasets, but also among datasets themselves. Our approach leverages the additional information on relationships informed by fine-tuning and transferability scores, and dataset similarity.
We reformulate the challenge of model selection as a graph link prediction problem. We propose TransferGraph4, which explores how the relationships among dataset-dataset and dataset-model can facilitate more effective model selection, offering a structured and intuitive method to navigate and un- derstand these complex relationships. To represent and analyze these intricate relationships, we represent them using graph structures. We show that TransferGraph is able to identify suitable pre-trained models for the target dataset by exploiting graph features learned from the graph structure and along with other metadata information (e.g., model architecture, data size). As shown in Figure 2, TransferGraph outperforms the state-of-the-art method [4] with a notable improvement in fine- tuning accuracy.
THE FRAMEWORK OF TRANSFERGRAPH
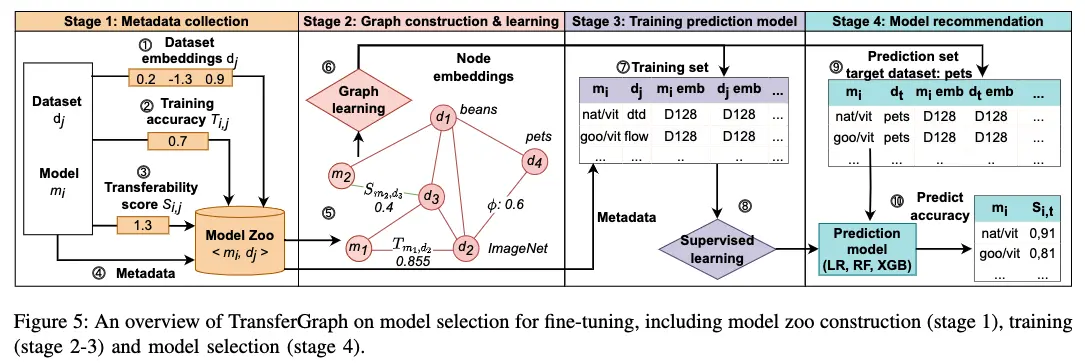
We propose TransferGraph, a framework that performs model selection via a graph learning process. There are a few steps in the graph-based model selection process, as shown in Figure 5. The processes are divided into four main steps: A. Metadata and Feature collection We first collect all the information needed, as described in Section IV. Step ①-④ indicate the collection process of different features and metadata used for the subsequent steps. Step ① obtains the dataset representations, which can be further applied to compute the similarity between datasets. Step ② encapsulates the training performance of models across different datasets, while step ③ represents the acquisition of transferability scores of models, which can be obtained from existing works, e.g., LogME [4]. Step ④ collects the metadata of models and datasets. All the collected information will be returned to the model zoo and stored as preparatory data for further processes.
Graph construction and learning
With the collected information, we continue to construct a graph in step ⑤, encapsulating relationships between models and datasets, and other attributes. The graph component and learning details are provided in Section V.
We embed different types of relationships in the graph. Datasets are connected to each other with edge weights encoding their similarity. Models are connected to datasets with weights of the training performance and/or transferability scores. To preserve the graph’s density and facilitate graph learning, we set specific heuristics during graph construction. These heuristics include setting thresholds to differentiate positive edges from negative ones, based on the edge weight. An positive edge between a model and dataset is established only when the normalized fine-tune accuracy and the transfer- ability score meet or exceed the threshold. The heuristics and properties of the constructed graph are shown in Table II. We further use one of the graph learners, e.g., Node2Vec, presented in Section V to capture the information in the graph, e.g., link structure or node features, as in step ⑥. The graph learner is trained for a link prediction task. With the trained graph learner, we extract the representations for each node, whose dimension is 128.
Training prediction model to predict model performance
As a learning-based strategy, we learn from the training history to predict the model performance on an unseen dataset as a regression task. In step ⑦, we construct a training set for the supervised learning as a regression task. The label is the training performance of a model on a dataset. The training features are constructed by metadata of models and datasets, as well as the node representations of the models and datasets. For example, given the performance of model mA on dataset dB , we identify the metadata of mA and dB , as well as the node representations of them. The information is treated as features and train a prediction model. The training set can be represented as tabular data. The prediction models are introduced below: We then can learn a prediction model, e.g., linear regression, random forest, on the prepared training set, as shown in step ⑧.
Linear regression. One of the prediction model we use is linear regression. We use the linear regression model to learn various features, e.g., meta features and graph features. Linear regression fits a straight line or surface that minimizes the discrepancies between predicted and actual output values.
Random forest. Random forest is also a highly adopted model due to its simplicity and explainability. We set the number of trees as 100, max depth as 5.
XGBoost. XGBoost (eXtreme Gradient Boosting) is one of the ensemble learning methods and is particularly effective in structured and tabular data scenarios [33]. XGBoost is an ensemble of decision trees and minimizes the objective function with gradient descent. We set the number of trees as 500, and maximum depth as 5.
Model recommendation for fine-tuning
We construct a prediction set ⑨ similarly to the training set construction. Especially, the dataset included in the pre- diction set is the target dataset we want to predict the model performance on. We adopt a leave-one-out approach for the evaluation of our methodology. When training the prediction model, we utilize all the fine-tuning results from the pairs of models and datasets, excluding the target dataset. In the prediction set, we predict the performance of pairs between all models and the target dataset, i.e., dt. The metadata of the dataset also adjust with the target dataset. We include all the models, since we would like to predict performance of the models in the model zoo on the target dataset. More details of the evaluation can be found in Section VII-A(Evaluation). Given the trained prediction model, we obtain a score for each model and target dataset pair. We apply these predicted scores as an indicator to rank and select models for fine-tuning.
Conclusion
We explore the use of a graph-learning-based model selec- tion strategy within the model zoo framework and introduce a comprehensive framework to address the intricate model selection problem. Predicting model performance proves to be challenging, given no dominant model excels across all datasets. Extensive experiments have shown that effectiveness of leveraging the intrinsic relationships between models and datasets for predicting the model performance. The most competitive variant of our model selection strategy gains 32% increase in measuring the correlation of the predicted model performance and the fine-tuning results. Furthermore, the graph-learning-based model selection strategy can contin- uously be improved with more metadata and training history in the model zoo.
More evaluation results can be seen here.